
生成AIの急速な普及により、私たちの生活や業務は飛躍的に効率化されています。しかし、大規模言語モデル(LLM)には固有の限界があります。学習時点の情報に基づいているため最新のデータが反映されない、特定の組織や分野に特化した詳細情報の不足、そして事実と異なる情報を堂々と生成してしまう「ハルシネーション」という課題です。
この問題に対して、現在急速に注目を集めている解決策が「RAG(Retrieval-Augmented Generation:検索拡張生成)」です。
RAGは、人間が「調べてから答える」プロセスをAIで実現する画期的な技術です。AIが外部の信頼できる知識ベースから関連情報を検索し、その情報を基に正確で最新の回答を生成します。これにより、ハルシネーションのリスクを大幅に軽減し、AIの回答に透明性と説明可能性をもたらします。本記事では、なぜRAGが今これほどまでに注目されているのか、その基本概念から具体的な導入事例まで徹底解説します。
RAGとは?その基本概念と重要性
RAGの定義
RAG(Retrieval-Augmented Generation:検索拡張生成)とは、大規模言語モデル(LLM)と検索システムを組み合わせ、より正確で信頼性の高い情報を生成するAI技術です。
その名の通り、RAGは「検索(Retrieval)」と「生成(Generation)」の2つのステップで動きます。
まずAIは、外部の知識ベースから質問に関連する情報を探し出します。ここでいう「外部」とは、AIが元々持っている知識(学習済みのパラメータ=内部知識)とは別に参照するデータソースのことです。たとえば、問い合わせ履歴やマニュアル、社内規定などが該当します。
人間にたとえるなら、
- 内部知識はこれまで勉強して覚えたこと(頭の中の記憶)、
- 外部知識は辞書や参考書、会社のマニュアル、製品資料。
AIはまずこの外部の資料を“取り出して”参考にし(検索)、それをもとに自分の知識と組み合わせながら自然な文章として答えをまとめる(生成)のです。
つまりRAGは「記憶だけで答えるAI」ではなく、「調べ物をしてから答えるAI」と考えるとわかりやすいでしょう。
このRAGの概念は、2020年にMeta AIによって発表された論文で提唱されました。それ以前のLLMは、学習したデータのみに基づいて回答を生成するため、最新の情報や専門的な知識に弱く、「ハルシネーション」と呼ばれる事実に基づかない情報を生成する問題が大きな課題となっていました。この問題に対する根本的な解決策として登場したのがRAGなのです。
RAGが注目される理由
RAGがこれほどまでに注目される最大の理由は、情報の信頼性と最新性を劇的に向上させる点にあります。従来のLLMが持つ「ハルシネーション」という弱点を克服し、ユーザーが求める正確な回答を提供できるようになります。この技術の利点を要約すると、以下の3点が挙げられます。
- 情報の信頼性向上とハルシネーション抑制:
外部データベースを参照するため、根拠に基づいた回答が可能になり、AIの「嘘」を大幅に減らすことができます。 - コスト効率の良さ:
モデル自体の再学習が不要なため、ファインチューニングに比べて時間とコストを大幅に削減できます。 - リアルタイム性の確保:
データベースを更新するだけで最新の情報を反映できるため、常に鮮度の高い情報を提供できます。
たとえば、企業のカスタマーサポートにRAGを導入すれば、製品マニュアルやFAQ、過去の問い合わせ履歴など、社内の膨大なドキュメントから最適な回答を自動で生成できます。これにより、顧客は迅速かつ的確なサポートを受けられ、企業の対応品質も向上します。
RAGは、単なる技術トレンドにとどまらず、AIのビジネス活用を次のステージへと引き上げる重要な役割を担っています。今後は、RAGの技術を基盤とした、より専門的で信頼性の高いAIアシスタントや情報検索システムが、あらゆる産業で不可欠な存在となるでしょう。
RAGの仕組みとプロセス
RAGは、その名の通り、検索フェーズと生成フェーズという2つの主要なプロセスで構成されています。この2つのフェーズが連携することで、LLMの弱点である「ハルシネーション(AIの嘘)」を克服し、信頼性の高い回答を導き出します。
検索フェーズの役割
検索フェーズの主な役割は、ユーザーの質問に対し、回答の根拠となる関連情報を外部の知識ベースから効率的に収集することです。このプロセスは、まるで図書館で特定のテーマに関する資料を探すようなものです。
まず、ユーザーからの質問は、ベクトル埋め込みという手法を用いて、コンピュータが理解できる数値のベクトルに変換されます。次に、このベクトルを使って、社内ドキュメント、Webサイト、PDFファイルといった外部データベースに保存された情報の中から、意味的に最も近い情報を高速で検索します。関連情報の収集方法としては、セマンティック検索やキーワード検索などが用いられますが、特に意味の類似度を重視するセマンティック検索がRAGでは重要な役割を果たします。
検索結果の評価基準は、主に関連度と網羅性です。ユーザーの質問にどれだけ的確に関連しているか、また、回答に必要な情報が十分に揃っているかどうかが問われます。質の高い検索結果は、その後の生成フェーズで精度の高い回答を生み出すための不可欠な要素となります。
生成フェーズの重要性
生成フェーズは、検索フェーズで収集した情報を基に、LLMが最終的な回答を組み立てるプロセスです。このフェーズがRAGの真価を発揮する場所であり、単なる情報羅列ではなく、人間が理解しやすい自然な文章として成果物をまとめ上げます。
生成プロセスのステップは以下の通りです。
- プロンプト構築:
検索で得られた関連情報とユーザーからの質問を組み合わせて、LLMへの指示(プロンプト)を生成します。 - 回答生成:
構築されたプロンプトに基づいて、LLMが回答を作成します。 - 情報整理と整形:
生成された回答を、論理的な構成、読みやすさ、誤字脱字の確認などを行い、最終的な成果物として仕上げます。
このフェーズの成果物は、単なる質問への回答にとどまりません。例えば、カスタマーサポートでの顧客対応文案、社内向けの情報共有レポート、あるいはブログ記事の草稿など、多岐にわたる活用方法が提案できます。生成フェーズを経ることで、収集した情報が実用的なコンテンツへと姿を変えるのです。
RAGの全体的なフロー
下記は、ユーザーの質問から始まり、最終的な回答が生成されるまでのRAGの一連の流れを示した図です。
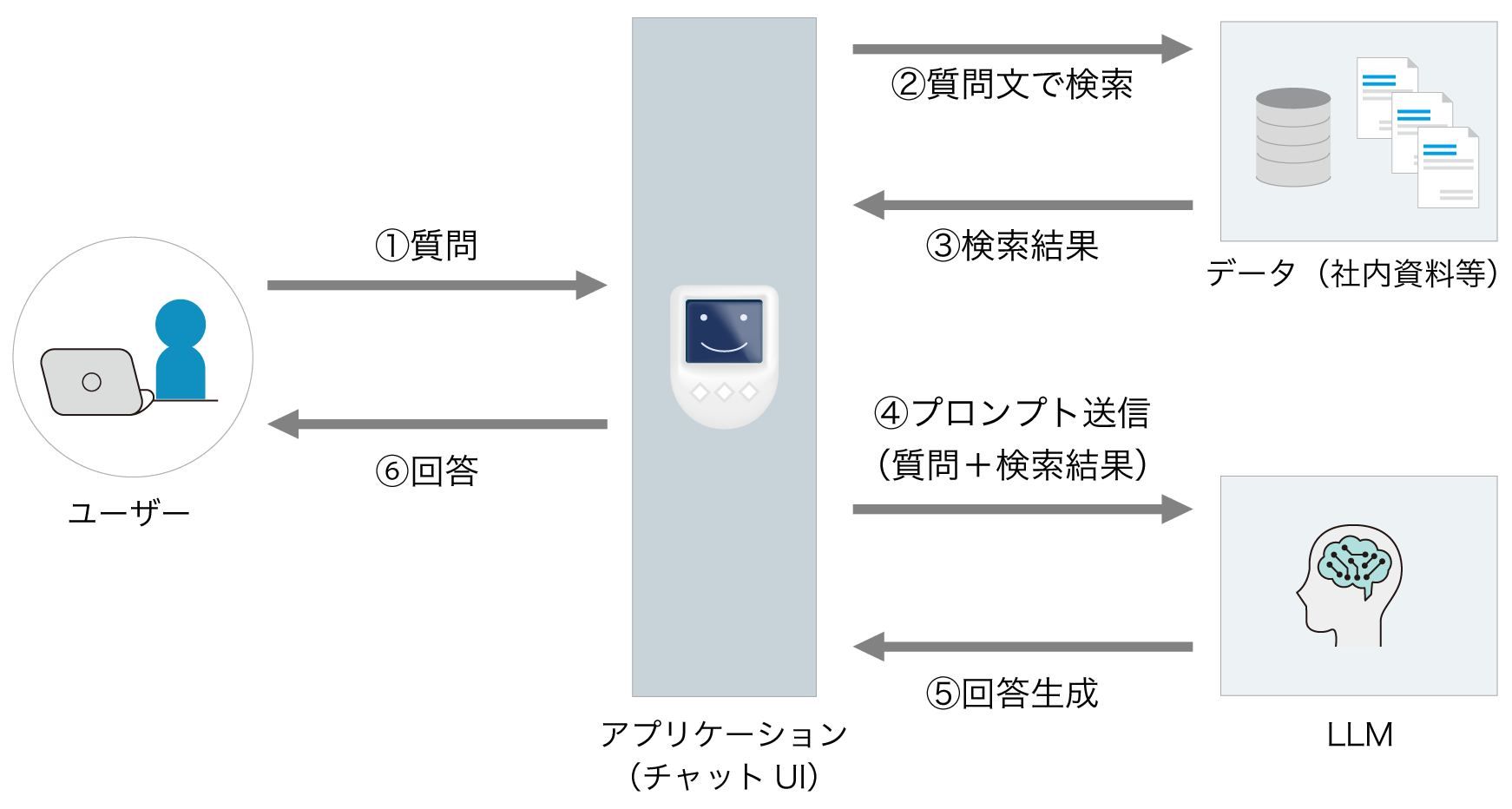
上記のフローチャートが示すように、ユーザーからの質問が入力されると、まず②と③の検索フェーズにて、質問に関連した情報が抽出されます。次に、この情報が④と⑤の生成フェーズにて、LLMの持つ知識と組み合わされ、検索フェーズで抽出した情報に基づいた回答が生まれます。各フェーズは独立しているのではなく、情報の流れによって密接に連携しています。検索フェーズの精度が低いと、生成フェーズでいくら優秀なLLMを使っても、質の高い回答は期待できません。
このフローをさらに改善する方法としては、検索結果のランク付けアルゴリズムを高度化することに加え、生成された回答に対してユーザーが行った評価や修正を記録し、それを次回以降の検索や生成の精度向上に役立てる仕組みを導入することが挙げられます。こうしたサイクルを繰り返すことで、RAGシステムの精度と信頼性は継続的に向上していきます。

RAGと他の技術との違い
AI技術の世界では、日々新しい手法やアプローチが登場しています。その中で、RAGは既存の技術とどのように異なるのでしょうか。ここでは、RAGと混同されやすいファインチューニング、そしてセマンティック検索という二つの主要な技術を比較し、それぞれの違いを明確に解説します。
ファインチューニングとの比較
ファインチューニングとは、事前に学習された大規模な言語モデルを、特定のタスクやドメインに特化した小規模なデータセットで再学習させる手法です。モデルの内部パラメータを更新することで、そのモデルが持つ知識を特定の分野に深く学習させることが可能になります。
一方、RAGは言語モデルの内部パラメータを直接変更しません。代わりに、外部データベースから参照した最新の情報をプロンプトに組み込み、その情報に基づいて回答を生成します。つまり、RAGはモデルの学習プロセスではなく、生成プロセスに「知識」を注入する仕組みです。
両者の利点と欠点を比較すると、以下のようになります。
- ファインチューニングの利点:
特定の専門分野において非常に高い精度を実現でき、プロンプトに情報を含める必要がないため応答が速い。 - ファインチューニングの欠点:
モデルの再学習に時間とコストがかかる。最新情報を反映するには再学習が必要で、古い情報を忘れてしまう可能性がある(破滅的忘却)。 - RAGの利点:
最新の情報を常に反映できる。学習プロセスが不要なため、導入や更新が容易でコストも低い。回答の根拠を提供できる。 - RAGの欠点:
外部データベースの質に依存する。検索ステップが追加されるため、応答がわずかに遅くなることがある。
セマンティック検索との違い
セマンティック検索とは、単なるキーワードの一致ではなく、質問の意味や文脈を理解して関連性の高い情報を探し出す技術です。たとえば、「ニューヨークで美味しいピザ屋を探している」という質問に対し、キーワード「ピザ屋」だけでなく、ニューヨークの地域情報や「美味しい」という評価に関連する情報を検索します。
RAGは、このセマンティック検索を機能の一部として利用します。しかし、ここが重要なポイントです。セマンティック検索は「情報を見つける」ことを目的としていますが、RAGは「見つけた情報を基に、新しい文章を生成する」ことを目的としています。より精度の高い回答を生成するためには、最適な情報を見つけることが不可欠です。
- セマンティック検索の用途:
社内文書から特定の資料を見つけ出す、Webサイトで関連する記事や商品を検索する、といった情報探索が主な目的です。結果は文書やリンクの一覧として提供されます。 - RAGの用途:
複数の資料を基に質問に回答する、複雑な内容を要約する、レポートを作成する、といった生成的な作業が主な目的です。結果は人間が書いたような正確で自然な文章として提供されます。
つまり、セマンティック検索はRAGの「目」の役割を果たすものであり、RAGは「見つけた情報を基に文章を書く」というタスクを実行するシステムなのです。
RAGのメリットとデメリット
RAGは、既存の大規模言語モデルの課題を解決する、拡張性に優れた機能ですが、その導入にはメリットとデメリットの両方を理解することが不可欠です。
RAGのメリット
RAGを導入する最大のメリットは、情報の信頼性と即時性の向上です。
- 情報の迅速な取得が可能:
インターネット上の最新記事や企業の社内文書といった外部データベースを参照して情報を取得します。これにより、モデルを再学習させることなく、常に最新の情報を反映した回答を生成できます。 - 多様なデータソースの統合:
PDF、Word、テキストファイル、Webサイトなど、さまざまな形式のデータを統合して利用できます。これにより、特定のドメインに特化した専門的な知識ベースを簡単に構築し、生成される回答の精度を高められます。 - ユーザーのニーズに応じたカスタマイズ:
RAGは、特定の企業や組織のニーズに合わせて、参照するデータを柔軟に変更できます。たとえば、特定の製品に関するカスタマーサポートボットを構築する際、その製品のマニュアルやFAQデータのみを参照させることで、より専門的で的確な回答を生成できます。
RAG運用上の注意点
RAGは多くのメリットを持つ一方で、運用上のいくつかの注意点も存在します。
- 情報の正確性の問題:
RAGの回答の精度は、参照するデータベースの質に大きく左右されます。もし参照するデータに誤りや古い情報が含まれていれば、生成される回答も不正確になる可能性があります。この仕組みは「Garbage in, garbage out(質の悪い情報を入れれば、質の悪い結果が出る)」という原則に当てはまります。 - データの偏りによる影響:
参照するデータが特定の視点や情報源に偏っている場合、生成される回答もその偏りを反映してしまうことがあります。公平で客観的な回答を実現するためには、多様でバランスの取れたデータセットを維持する必要があります。 - 運用コストの増加:
RAGシステムを効果的に運用するには、参照するデータベースの管理と更新が不可欠です。質問に最適な回答を生成するためには、この機能を継続的に行うための人的コストや、データベースのインデックスを維持するための計算コストが発生します。

RAGの活用事例
RAGは、その高い信頼性と情報鮮度から、ビジネスのさまざまな場面で活用されています。ここでは、RAGの具体的な応用事例を3つの分野に分けて解説します。
カスタマーサポートにおけるRAGの活用
カスタマーサポートは、RAGが最も力を発揮する分野の一つです。RAGを導入することで、顧客からの問い合わせに対して、人間のような自然な会話で的確な回答を生成するAIチャットボットを実現できます。
【導入のステップ】
1.データ準備:既存のFAQ、マニュアル、過去の問い合わせ履歴などを収集・整理し、データベース化します。
2.ベクトル化:データをベクトル(数値)に変換し、ベクトル検索システムを構築します。
3.モデル連携:LLMとベクトル検索システムを連携させ、ユーザーの質問に応じて適切な回答を生成する仕組みを構築します。
社内情報検索の効率化
RAGは、社内にある膨大な文書から必要な情報を迅速に見つけ出すための強力なツールです。従来のキーワード検索では見つけられなかった、意味的に関連性の高い情報を探し出すことが可能になります。
【導入時のポイント】
データの管理とセキュリティ:RAGの精度を高めるためには、参照する情報を管理し、常に最新の状態に保つことが重要です。また、機密情報を含む文書を扱う場合は、セキュリティを確保し、ユーザーの役割に応じた適切なアクセス権限を設定する必要があります。

コンテンツ生成におけるRAGの役割
RAGは、ブログ記事、ニュースレター、レポートなどのコンテンツを生成する際にも有効な機能です。事実に基づいた正確な情報を参照しながら、クリエイティブな文書を生成できます。
【導入のステップ】
1.情報収集:ユーザーがテーマやキーワードを入力すると、RAGがインターネットや外部データベースから関連情報を検索します。
2.情報整理:検索で得られた複数の情報を要約し、記事の構成案や骨子を組み立てます。
3.コンテンツ生成:骨子に基づいてLLMが文書を生成します。

RAG導入のステップ
RAGを効果的に導入するには、単に技術を導入するだけでなく、体系的なプロセスを踏むことが不可欠です。ここでは、RAG導入の主要なステップを3つに分けて解説します。
1. データベースの選定と構築
RAGの精度は、参照するデータベースの質に直接左右されます。そのため、最初のステップとして、目的に合ったデータベースを選定し、適切に構築することが極めて重要です。
まず、RAGの導入目的を明確にし、それに合わせてデータベースの種類を選びます。たとえば、企業の社内文書を扱う場合は、PDFやテキストファイルを格納できるデータベースが適しています。一方、Webサイトの情報をリアルタイムで参照したい場合は、クローリングとインデックス作成の機能を持つシステムが必要になります。
次に、データベースに格納するデータの質を確認します。古かったり、誤りがあったり、偏ったデータは、誤った情報を生成する原因となるため、事前にクレンジング(データの確認と修正)を行う必要があります。
最後に、将来的なデータの増加や、ユーザー数の増加に対応できるスケーラビリティを考慮します。RAGシステムが大規模に成長した場合でも、安定したパフォーマンスを維持できるデータベースを選ぶことが成功の鍵となります。
2. プロンプト設計の重要性
プロンプト設計は、RAGシステムから質の高い回答を引き出すための最も重要なステップの一つです。どれだけ優れたデータベースがあっても、LLMへの指示(プロンプト)が不明確では、期待する結果は得られません。
プロンプト設計では、まずユーザーのニーズを深く理解することが求められます。どのような質問に対して、どのような形式や粒度の回答を求めているのかを分析します。
次に、ユーザーのニーズに合わせて、LLMに明確で具体的な指示を提供します。たとえば、「〇〇について教えてください」という漠然とした質問ではなく、「〇〇の利点と欠点を要約し、箇条書きで回答してください」といった具体的な指示を付加することで、より精度の高い回答が生成されます。
また、ユーザーからのフィードバックを活用することも重要です。回答がユーザーのニーズに合わなかった場合は、その理由を分析し、プロンプトを改善することで、システムのパフォーマンスを継続的に向上させることができます。
3. システムのテストと改善
RAGシステムの性能を最大化するためには、導入後の継続的なテストと改善が不可欠です。
まず、様々な質問パターンを想定したテストケースを設定し、システムの回答精度を客観的に評価します。テストは、シンプルな事実確認から、複数の情報を組み合わせる複雑な質問まで、幅広く行うことが推奨されます。
テストで得られた結果を分析し、システムの弱点や改善点を特定します。たとえば、特定のトピックでハルシネーションが発生しやすい、特定の形式の文書の参照が苦手、といった課題を特定できます。
最後に、これらの分析結果を基に、データベースの改善、プロンプトの再設計、LLMのチューニングなど、継続的な改善を行うことで、RAGシステムの精度と信頼性を段階的に高めていきます。
RAGの精度向上のためのポイント
RAGシステムは、導入して終わりではありません。そのパフォーマンスを最大限に引き出すには、継続的な改善が不可欠です。ここでは、RAGの精度を高めるための2つの重要なポイントを解説します。
データの質を高める方法
RAGの回答精度は、参照するデータの質に直接依存します。システムの精度を向上させるには、RAGの土台となるデータベースの質を見直すことが最も効果的です。
- データの収集源を見直す:
まず、現在のデータ収集源が目的に適しているか再検討します。たとえば、最新のニュースやトレンドに関する回答を生成したい場合、リアルタイムで情報が更新されるWebサイトやニュースフィードを新たな参照源として追加することが効果的です。信頼性の低い情報源は除外することで、ハルシネーションのリスクを減らせます。 - データのクリーニングを行う:
データベースに誤字脱字、古い情報、重複した情報などが含まれていないか確認します。これらのノイズは、RAGが不正確な情報を参照する原因となります。定期的にデータをクレンジングすることで、回答の正確性が向上します。 - 多様なデータセットを使用する:
AIに偏りのない回答を生成させるためには、多様な視点を持つデータセットが必要です。複数の情報源からデータを収集し、統合することで、より包括的でバランスの取れた回答を実現できます。
プロンプトエンジニアリングの活用
質の高いデータベースがあっても、LLMへの指示が不適切では、期待する結果は得られません。プロンプトエンジニアリングは、LLMの能力を最大限に引き出すための重要な技術です。
- プロンプトの設計を工夫する:
ユーザーの質問だけでなく、どのような形式で回答を求めているか(例:箇条書き、要約、比較表など)をプロンプトに含めます。具体的な指示は、LLMが回答を生成する際の指針となります。 - 具体的な指示を与える:
「〇〇について教えてください」といった漠然とした質問ではなく、「〇〇の技術的なメリットとデメリットをわかりやすく要約し、500字以内で回答してください」のように、具体的な制約や条件を指示することで、より精度の高い回答が生成されます。 - フィードバックを活用する:
ユーザーや開発者からのフィードバックは、プロンプトを改善するための貴重な情報です。「なぜこの回答は不適切だったのか?」を分析し、プロンプトに改善を加えていくことで、RAGシステムの精度を継続的に高めることができます。
RAGを成功に導くための実践ガイド
RAG技術は、単なる情報の効率化ツールにとどまらず、ビジネスのあり方を根本から変える可能性を秘めています。この進化の波に乗り、競争優位性を築くためには、以下の3つのステップを実践することが重要です。
データ駆動型の戦略を確立する
RAGのパフォーマンスは、その核となるデータベースの質に大きく左右されます。未来を見据えた活用のためには、価値ある情報を戦略的に構築する意識が不可欠です。
- データの多様化:
テキストだけでなく、画像や音声といったマルチモーダルなデータに対応できるよう準備を進めましょう。多様な情報源から、よりリッチで包括的な回答を生成できるようになります。 - データのパーソナライズ:
ユーザーの行動や好みを学習させることで、個別最適化された情報提供が可能になります。これにより、顧客サポートやマーケティング活動が飛躍的に進化します。
スモールスタートで確実な成功体験を積む
大規模な投資をいきなり行うのではなく、まずは小さく始めて成功体験を積み重ねることが、RAG導入の鍵です。
- 具体的な導入例:
部署内のナレッジ共有システムや、特定のFAQ対応など、スコープを絞ったプロジェクトから始めましょう。これにより、リスクを抑えつつ、RAGの有効性や課題を具体的に把握できます。 - 段階的な拡大:
小規模プロジェクトで得られた知見をもとに、顧客向けカスタマーサポートや社内トレーニングツールなど、より大きなビジネスインパクトを生む領域へと徐々に拡大していきましょう。
継続的な改善サイクルを回す
RAGは、「作って終わり」のシステムではありません。常に改善し続けることで、最高のパフォーマンスを維持できます。
- フィードバックの活用:
ユーザーからのフィードバックを積極的に収集し、データベースの更新やプロンプトの調整に活かしましょう。 - システムの改善:
最新の研究動向や、新しいモデル、ツールに常にアンテナを張り、自社のシステムに取り入れることで、陳腐化を防ぎ、常に最高のパフォーマンスを維持できます。
これらのステップを踏むことで、RAGは単なる業務効率化ツールではなく、あなたのビジネスを次のステージへと導く強力なパートナーとなるでしょう。
まとめ:RAGの重要性の再確認
これまでの解説でRAGの仕組みや活用事例について理解を深めてきました。ここで、改めてRAGがなぜ現代のAIにおいて不可欠な存在なのか、その重要性を再確認しましょう。
RAGは、LLMが持つ知識の限界を克服するために開発された技術です。RAGはAIが外部のデータベースから最新の情報や特定の情報を検索し、その情報を参照しながら回答を生成します。この仕組みにより、RAGは学習したデータに依存することなく、正確で信頼性の高い情報を提供できます。
RAGの最大のメリットは、AIの回答における情報の「正確性」と「最新性」を劇的に向上させる点です。これにより、AIが事実と異なることを生成するハルシネーションを大幅に抑制できます。また、モデルを再学習させる必要がないため、導入や更新が容易であり、コストも抑えられます。これは、情報が日々更新されるビジネスにおいて、迅速な対応を可能にする強力な武器となります。
RAGはすでに、多岐にわたる分野で実用化されています。例えば、カスタマーサポートでは、顧客からの質問に対し、最新の製品マニュアルやFAQを参照して自動で回答を生成します。これにより、顧客満足度とサポート業務の効率が同時に向上します。また、社内の情報検索では、膨大な社内資料から必要な情報を瞬時に見つけ出し、従業員の業務を効率化します。
RAGの導入は、企業の業務効率化や顧客サービスの向上を実現するための重要な一歩です。もし、RAGに関する具体的な導入プロセスや、自社に最適なチャットボット製品の選び方など、さらに詳しく知りたい点がございましたら、お気軽にご相談ください。
RAGを導入したいならイクシーズラボのCAIWA Service Viii
AIチャットボットの先駆者として豊富な実績と経験をもつ株式会社イクシーズラボは、運用が容易で高性能なCAIWA(カイワ)シリーズを展開しています。
イクシーズラボの提供するCAIWA Service Viiiは、RAG技術を活用した「ChatGPT連携機能」を備えていて、社内データを活用し構築運用の手間なく企業固有の問い合わせ対応を自動化できます。なお、このRAG機能には、ハルシネーションを回避する仕組みが整っているため安心して利用できるようになっています。
高度なAI技術が組み込まれたCAIWA Service e Viiiを導入することで、ナレッジの有効活用と業務効率化を効果的に実現できます。
ハルシネーション対策が整ったRAG機能搭載!
AIチャットボットCAIWA Service Viii
Viiiは、導入実績が豊富で高性能なAIチャットボットです。学習済み言語モデル搭載で、ゼロからの学習が必要ないため、短期間で導入できます。導入会社様からは回答精度が高くメンテナンスがしやすいと高い評価をいただいています。
社内ナレッジの活用と共有を促進
AIナレッジエージェントCAIWA Service Qrea
QreaはRAG技術を活用したAIエージェントです。知りたいことを尋ねるだけで、関連するドキュメントを検索してリスト化し最適なものを選定。さらに、ドキュメント内から質問に即した情報を抽出し、わかりやすい回答形式で提示します。
